1 数据库的一些基础概念
1.1 数据库和数据库管理系统
A database-management system (DBMS) is a collection of interrelated data and a set of programs to access those data.
It is a powerful tool for managing large amount of data efficiently and allowing data to persist safely.
Database refers to a collection of data that is managed by a DBMS
数据库是一组相关数据的集合,而数据库管理系统(DBMS)是管理、维护和操作这些数据的软件系统。简单来说,数据库是数据的集合,而DBMS是用来管理和操作这些数据的工具。
1.2 关系模式和关系实例
关系模式(Relation Schema)和关系实例Relation Instance是关系型数据库中的两个不同但相关的概念。
A relation schema (关系模式) consists of a list of attributes and their corresponding domains.It defines the structure of the table, but does not include any actual data.
关系模式(Relation Schema)是指关系型数据库中表格的结构,包括表格的名称、列名、数据类型、主键和外键等。它定义了表格的结构,但并不包含任何实际的数据。关系模式通常通过CREATE TABLE语句来定义。
A relation instance (关系实例) is a set of tuples over a relation schema
关系实例(Relation Instance)是指关系模式中表格中的具体数据,也就是表格中的行和列。它是关系模式的一个具体实例,包括表格中的所有数据。关系实例可以通过SELECT语句来检索和查询。
例如,假设我们有一个关系模式为“学生(Student)”,包括学生编号(Student ID)、姓名(Name)、年龄(Age)和性别(Gender)等列。那么,关系实例就是表格中的具体数据,如学生编号为001、姓名为张三、年龄为20岁、性别为男性等。
1.3 数据库模式和数据库实例
数据库模式(Database Schema)是数据库的结构图,它描述了数据库中各个表、列、主键、外键等的结构和关系。也就是说,数据库模式定义了数据库中数据的逻辑结构,包括表格、关系、约束和索引等元素。它是一个静态概念,不会发生变化,除非进行数据库结构的修改。
Database schema (数据库模式) – is the logical structure of the database
数据库实例(Database Instance)是指在计算机内存中运行的数据库,它是数据库在运行时的状态。也就是说,数据库实例包含了数据库中所有数据的副本以及处理这些数据的进程和线程。每个数据库实例都有自己的内存空间和处理器资源,可以独立地进行处理和管理。
Database instance (数据库实例) – is a snapshot of the data in the database at a given instant in time.
2 数据库组织形式
2.1 数据采用文件的缺点
1 获得数据很困难,得为每一个潜在的程序写代码程序
Difficulty in accessing data
2 数据丢失或者不一致
Data redundancy and inconsistency
3 完整性问题
Integrity problem
4 并发访问,或者操作到一半的时候可能会出现程序崩掉,这时候数据库可能会把前面未完整执行的进行执行
Concurrent-access problem
5 安全访问问题
Security problem
6 操作原子性问题
Atomicity problem
2.2 使用数据库管理系统的 优点
主要是两方面
便于查询和修改数据
便于确定数据逻辑结构
支持大量数据
访问控制
原子性操作
即事务是原子的。原子性是指事务中的所有操作被视为一个单独、不可分割的操作,要么全部执行成功,要么全部失败回滚,不会出现部分执行的情况。
这意味着,如果一个事务包含多个操作,如果其中任何一个操作失败,整个事务就会回滚,回到原始状态,所有的操作都会取消。这种方式可以确保数据的一致性和完整性,避免了数据损坏或错误的情况。
3 关系型数据库特点
- 数据以表格(表)的形式存储,其中每个表包含行和列,每个表有独一无二的名称
- 表之间可以建立关系,通过外键(foreign key)实现表之间的连接。
- 数据库使用结构化查询语言(SQL)进行查询和操作。
- 关系型数据库通常支持事务处理和数据完整性控制。
4 三个层次的数据抽象Data Abstraction
Logical level:users can see all tables and how they are related
比如数据表的组织方式
Physical level: describe how data is stored in a file.
比如某一个内容占据多少字节等等
View level: users can see the tables within the scope of their requirements and permissions.
比如教师可以看到教师的数据表,而学生只能看到学生的数据表
5 超键、候选码、主码、外码
超键
在关系型数据库中,超键(Superkey)是能够唯一标识一个关系中元组的一组属性集合。简单来说,超键是可以唯一区分关系模式中不同元组的一组属性。
超键具有以下特点:
- 超键必须是唯一的,即在关系模式中没有两个元组具有相同的超键值。
- 超键可以包含一个或多个属性。
- 超键可以是候选键(Candidate Key)的超集,也可以是包含主键(Primary Key)的超键。
注意这里是超键的每一个子集都一样
ID,ID2,姓名,年龄,性别
候选码
最小的超键,可以有多个
主码
从候选码里选出来,唯一的一个 主码是数据库表中的一个字段或一组字段,用于唯一标识表中的每一行记录。
主码是数据库表中唯一标识记录的字段或字段集合,每个表只能有一个主码。候选码也是具有唯一性的字段或字段集合,但一个表可以有多个候选码,其中一个通常会被选择为主码。主要区别在于主码是表的主要标识符,而候选码是备选的唯一标识符。
写一个关系模式,将主键用下划线画出来,且一般在其他元素前
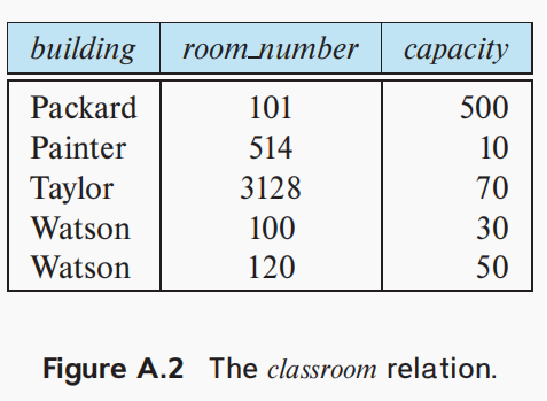
写出他的关系模式
注意这里,用 两个才能唯一区别building, room number同时画下划线
外码
“参照关系”和”被参照关系”是用来描述表之间关系的术语,它们涉及到外码(Foreign Key)和主码(Primary Key)之间的联系。以下是它们的解释:
参照关系(Referencing Relationship):
- “参照关系”指的是包含外码(Foreign Key)的表,该外码引用另一张表的主码(Primary Key)或候选码(Candidate Key)。
- 在参照关系中,外码字段存储了关联表的键值,它用于确立两个表之间的关联。
- 表示为:表A包含一个外码字段,该字段引用了表B的主码或候选码,这时表A就与表B存在参照关系。
被参照关系(Referenced Relationship):
- “被参照关系”指的是包含主码或候选码的表,该表的键值被外码字段引用,从而使其他表可以与它建立关联。
- 在被参照关系中,一个表的主码或候选码通常被其他表的外码引用,这表明它在其他表中作为关联的目标。
- 表示为:表B的主码或候选码被表A的外码引用,这时表B就与表A存在被参照关系。
例如,考虑以下两个表:Customers(客户)和Orders(订单)。Customers 表的 CustomerID 字段是主码,而 Orders 表的 CustomerID 字段是外码。这种情况下:
- Customers 表是被参照关系表,因为它的主码(CustomerID)被 Orders 表的外码字段(CustomerID)引用,允许订单表与客户表建立关联,以指示哪些客户下了哪些订单。
- Orders 表是参照关系表,因为它包含了外码字段(CustomerID),该字段引用了客户表的主码(CustomerID),用于建立订单表与客户表之间的关联。
总之,参照关系和被参照关系描述了表之间的关联,外码与主码之间的关系非常重要,它们有助于维护数据完整性,并允许查询和检索相关数据
一个关系数据库由多个表组成,每个表有自己独一无二的名字
一个表通常内概念有 属性,元组,分量
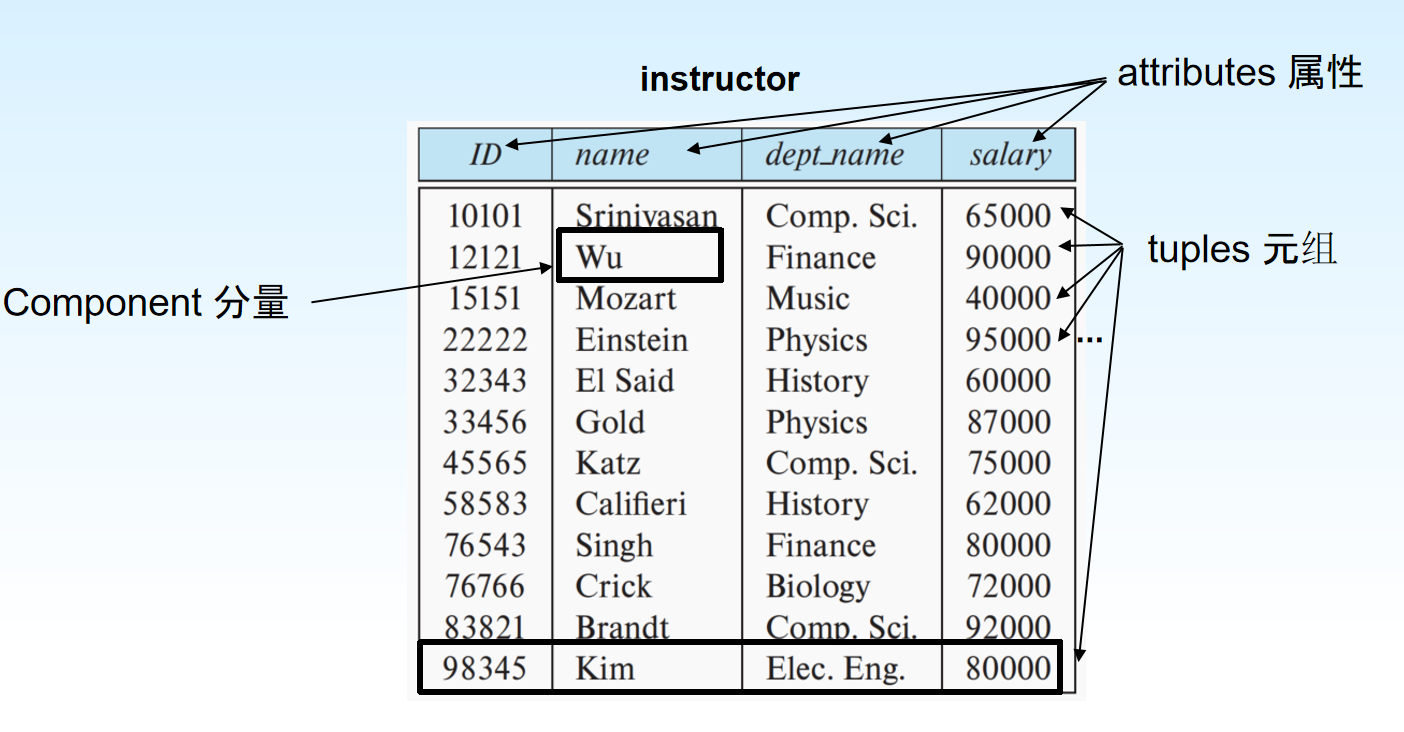
概念
属性的域(domain):属性允许的值的集合,比如年龄这个属性,允许的值是正整数
r 的所有属性的域都应该是原子的。什么原子的?域的元素被认为是不可分割的单元



